11.04.2025
11.04.2025
KI-Forschungsassistent mit dem DeepResearch-Workflow von PUNKU.AI
KI-Forschungsassistent mit dem DeepResearch-Workflow von PUNKU.AI

Erstellung eines leistungsstarken KI-Forschungsassistenten mit PUNKU.AIs DeepResearch-Workflow
TL;DR: Der DeepResearch-Workflow in PUNKU.AI integriert Claude mit leistungsstarken Web-Browsing-Funktionen, spezialisierten Wissenswerkzeugen und adaptiven Suchstrategien, um einen umfassenden Forschungsassistenten zu schaffen. Mit Firecrawl für die Web-Erkundung, zusammen mit Wikipedia, Wikidata, arXiv und Yahoo Finance, liefert dieser Workflow detaillierte, quellenbasierte Forschung zu jedem Thema.
Einleitung
In der informationsreichen Welt von heute erfordert gründliche Forschung das Navigieren durch riesige Datenmengen aus mehreren Quellen. Traditionelle Forschungsmethoden sind oft nicht effizient und umfassend. Der DeepResearch-Workflow von PUNKU.AI geht dieser Herausforderung nach, indem er einen KI-gestützten Forschungsassistenten schafft, der ausgeklügelte Web-Browsing-Funktionen mit Zugang zu spezialisierten Wissensquellen kombiniert.
Dieser Blogbeitrag wird erkunden, wie der DeepResearch-Workflow aufgebaut ist, seine Komponenten untersuchen und demonstrieren, wie er für umfassende Forschungsaufgaben genutzt werden kann. Wir werden in die technische Architektur eintauchen, die diesen Workflow antreibt, und zeigen, wie PUNKU.AIs visuelle Programmieransätze die Erstellung komplexer KI-Anwendungen vereinfachen.
Visuelle Darstellung des Workflows
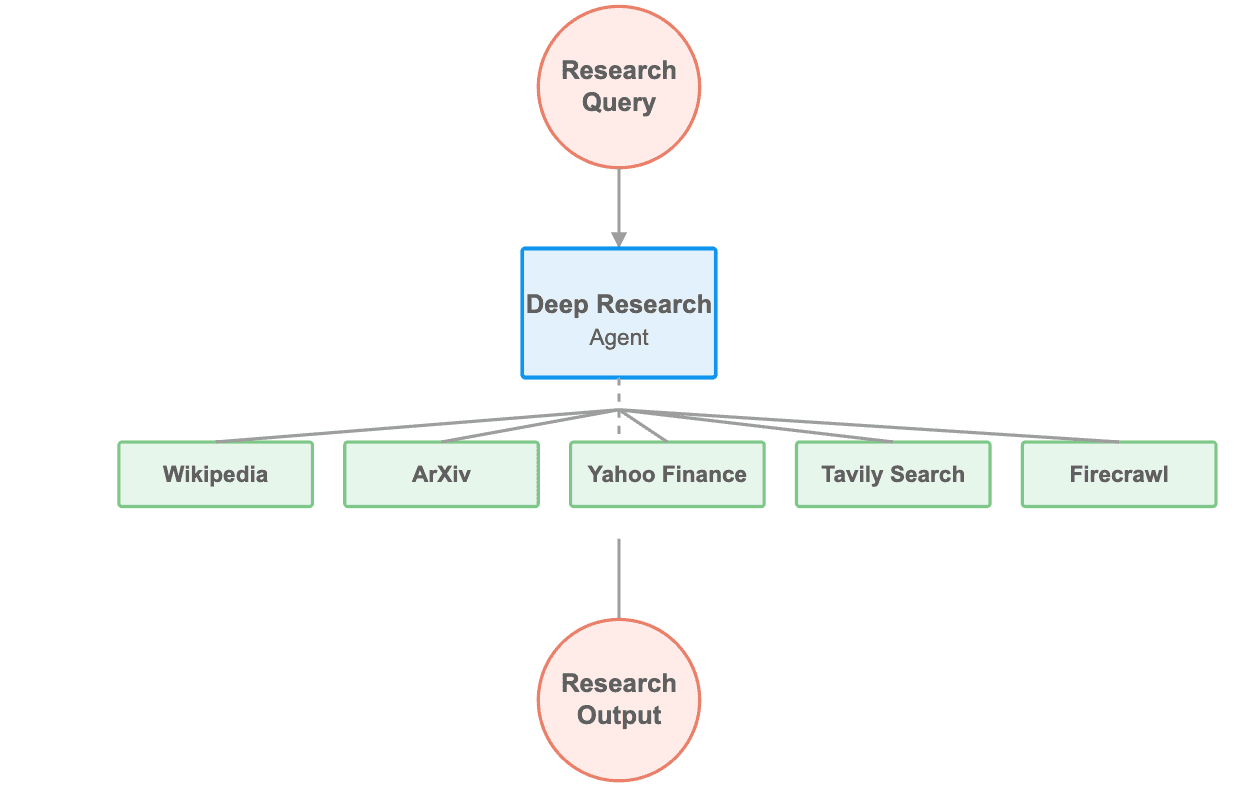
Das obige Diagramm veranschaulicht die Struktur des DeepResearch-Workflows, wobei der Deep Research Agent im Mittelpunkt verschiedene Werkzeuge orchestriert, um Benutzeranfragen zu verarbeiten und umfassende Forschungsergebnisse zu liefern.
Komponentenaufgliederung
Kernkomponenten
1. Deep Research Agent
Der Deep Research Agent ist der zentrale Koordinator des Workflows und wird von Claude (Anthropic) angetrieben, mit spezieller Konfiguration zur Bewältigung von Forschungsaufgaben.
"model_name": "claude-3-7-sonnet-20250219", "temperature": 0.1, "max_tokens": 5000, "max_iterations": 40
Dieser Agent orchestriert den Forschungsprozess, indem er:
Komplexe Fragen in kleinere, erforschbare Komponenten zerlegt
Die geeigneten Werkzeuge für jede Forschungsaufgabe auswählt
Den iterativen Forschungsprozess mit konfigurierbarer Tiefe verwaltet (Standard: 7 Iterationen)
Ergebnisse in umfassende, gut strukturierte Antworten synthetisiert
Die richtige Quellenangabe für alle Informationen bereitstellt
2. Chat-Eingabe- und Ausgabe-Komponenten
Chat-Eingabe: Nimmt Benutzeranfragen entgegen und leitet sie an den Forschungsagenten weiter
Chat-Ausgabe: Zeigt formatierte Ergebnisse dem Benutzer an, einschließlich aller Quellen
3. Systemaufforderung
Die Systemaufforderung gibt dem Agenten detaillierte Anweisungen, wie er Forschung durchführen, Quellen bewerten und Antworten formatieren soll:
Web-Erkundungswerkzeuge
1. Tavily AI-Suche
Diese Komponente bietet eine KI-optimierte Suchmaschine, die speziell für LLMs und RAG-Anwendungen entwickelt wurde:
Unterstützt grundlegende und erweiterte Suchtiefe
Konfigurierbares Ergebnisslimit und Zeitrahmen
Option, Bilder und Zusammenfassungsantworten einzuschließen
Strukturierte Ausgabe mit URLs, Titeln und Inhalten
2. Firecrawl-Komponenten
Der Workflow umfasst vier spezialisierte Firecrawl-Komponenten, die zusammenarbeiten, um umfassende Web-Browsing-Funktionen bereitzustellen:
FirecrawlMapApi: Kartiert die Website-Struktur, um relevante Seiten zu identifizieren
Erstellt Standortkarten für systematisches Navigieren
Identifiziert Inhaltsbeziehungen innerhalb von Domänen
Unterstützt Sitemap- und Subdomain-Erkundungsoptionen
FirecrawlCrawlApi: Durchsucht gesamte Websites für umfassende Inhaltsuntersuchungen
Folgt Links bis zur festgelegten Tiefe
Verarbeitet Crawler-Optionen wie Tiefe und Linkverfolgung
Konfigurierbare Timeout-Einstellungen (Standard: 3000 ms)
FirecrawlScrapeApi: Extrahiert Inhalte von bestimmten URLs
Ruft saubere, strukturierte Inhalte von Webseiten ab
Formatiert die Ausgabe als Markdown für konsistente Präsentation
Konzentriert sich auf den Hauptinhalt und filtert Navigationselemente und Anzeigen
FirecrawlExtractApi: Führt gezielte Extraktionen spezifischer Informationen durch
Extrahiert strukturierte Informationen mithilfe von Schemata
Verwendet Eingabeaufforderungen in natürlicher Sprache zur Anleitung der Extraktion
Unterstützt die Integration von Websuchen für zusätzlichen Kontext
Wissensdatenbank-Werkzeuge
1. Wikipedia-Komponente
Bietet Enzyklopädie-Wissen zu einer breiten Palette von Themen:
"lang": "en", "k": 4, "doc_content_chars_max": 4000
Konfigurierbare Sprachenauswahl (Standard: Englisch)
Anpassbare Ergebnismenge (Standard: 4 Artikel)
Inhaltslängenverwaltung mit Zeichenlimits
Gibt sowohl strukturierte Daten als auch formatierten Text zurück
2. Wikidata-Komponente
Greift auf strukturierte Daten über Entitäten und Konzepte zu:
Gibt Entitätsinformationen mit Bezeichnungen, Beschreibungen und Identifikatoren zurück
Bietet eindeutige Entitäts-IDs (Q-Nummern) für zuverlässige Referenzen
Beinhaltet Konzept-URIs und Wikidata-Seiten-URLs
Nützlich zur Identifizierung spezifischer Entitäten und ihrer Eigenschaften
Spezialisierte Forschungswerkzeuge
1. arXiv-Komponente
Durchsucht und ruft akademische Forschungsarbeiten ab:
"search_type": "all", "max_results": 10
Durchsucht Arbeiten nach Titel, Abstract, Autor oder Kategorie
Gibt umfassende Metadaten, einschließlich Abstracts, Autoren und Veröffentlichungsdaten, zurück
Bietet direkte Links zu PDF-Downloads und Zeitschriftenreferenzen
Konfigurierbares Ergebnisslimit (Standard: 10 Arbeiten)
2. Yahoo Finance-Komponente
Greift auf Finanzdaten und Marktinformationsressourcen zu:
"method": "get_news", "num_news": 5
Ruft Aktienkurse mit verschiedenen Methoden ab (Informationen, Nachrichten, Finanzberichte)
Unterstützt über 25 Methoden zur Datenabfrage, einschließlich Gewinnberichte, Dividenden und SEC-Einreichungen
Konfigurierbare Anzahl von Nachrichtenartikeln für die Nachrichtenabfrage
Strukturierte Ausgabe mit Titeln, Links und Inhalten
Workflow-Erklärung
Schritt-für-Schritt-Ausführungsfluss
Benutzereingabeverarbeitung:
Der Workflow beginnt, wenn ein Benutzer eine Forschungsfrage über die Chat-Eingabe-Komponente einreicht
Die Anfrage wird zusammen mit der Systemaufforderung und den verfügbaren Werkzeugen an den Deep Research Agenten übergeben
Forschungsplanung:
Der Agent analysiert die Anfrage und zerlegt sie in spezifische Forschungsbestandteile
Er bestimmt eine geeignete Forschungsstrategie, einschließlich der zu verwendenden Werkzeuge und deren Reihenfolge
Iterativer Forschungsprozess:
Der Agent führt die Forschung in mehreren Iterationen durch (konfigurierbare Tiefe)
Für jede Iteration folgt er einem systematischen Prozess:
SUCHE-Phase: Verwendet die geeigneten Suchwerkzeuge (Tavily, Firecrawl), um relevante Quellen zu finden
EXTRAKT-Phase: Extrahiert Inhalte aus identifizierten Quellen
ANALYSE-Phase: Analysiert die gesammelten Informationen und identifiziert Wissenslücken
PLAN-Phase: Bestimmt den nächsten Suchfokus basierend auf der Analyse
Informationssynthese:
Nach Abschluss der Forschungsiterationen synthetisiert der Agent alle Ergebnisse
Er organisiert die Informationen logisch und erstellt eine umfassende Antwort
Alle Quellen werden ordnungsgemäß mit URLs angegeben
Antwortgenerierung:
Die endgültigen Forschungsergebnisse werden mit klarer Struktur und Überschriften formatiert
Quellen werden in einem speziellen Abschnitt mit dem richtigen Zitationsformat angegeben
Die Antwort wird dem Benutzer über die Chat-Ausgabe-Komponente angezeigt
Datenumwandlungen
Der Workflow führt mehrere wichtige Datenumwandlungen durch:
Abfrage → Suchergebnisse:
Benutzeranfragen werden in mehrere Suchanfragen über verschiedene Werkzeuge umgewandelt
Suchergebnisse werden als strukturierte Daten mit URLs und Metadaten zurückgegeben
URLs → Inhalt:
URLs aus den Suchergebnissen werden verwendet, um vollständige Inhalte zu extrahieren
Inhalte werden bereinigt, formatiert und zum Analysieren strukturiert
Inhalt → Erkenntnisse:
Rohinhalte werden analysiert, um wichtige Fakten, Datenpunkte und Konzepte zu extrahieren
Die Analyse identifiziert Muster, Beziehungen und Wissenslücken
Erkenntnisse → Umfassende Antwort:
Einzelne Erkenntnisse werden in eine kohärente, umfassende Antwort synthetisiert
Informationen werden mit klarer Struktur und logischem Fluss organisiert
Alle Quellen werden ordnungsgemäß angegeben
Schlüsselmechanismen
1. Adaptive Suchstrategie
Der DeepResearch-Workflow verwendet eine adaptive Suchstrategie, die die geeignetsten Werkzeuge basierend auf dem Forschungsthema auswählt und den Suchfokus iterativ verfeinert:
# Simplified logic for tool selection if topic_is_academic: primary_tool = "arXiv" elif topic_is_financial: primary_tool = "YahooFinance" else: primary_tool = "TavilySearch"
2. Quellenverfolgung
Der Workflow führt eine sorgfältige Verfolgung aller Quellen, um sicherzustellen, dass jedes Informationsstück auf seinen Ursprung zurückverfolgt werden kann:
# Source tracking mechanism (simplified) for content in extracted_content: source_url = content.get("source") if source_url and source_url not in state["all_sources"]: state["all_sources"].append(source_url)
3. Deep Research Loop
Der iterative Forschungsprozess wird durch eine strukturierte Schleife verwaltet, die fortgesetzt wird, bis ausreichend Informationen gesammelt sind oder die maximale Tiefe erreicht ist:
# Deep research loop (simplified) while state["current_depth"] < state["max_depth"]: state["current_depth"] += 1 search_results = await search_web(query) extracted_content = await extract_from_urls(search_results) analysis = await analyze_and_plan(extracted_content) if not analysis["should_continue"]: break query = analysis["next_search_topic"]
Anwendungsfälle & Anwendungen
Der DeepResearch-Workflow kann auf eine Vielzahl von Forschungsszenarien angewendet werden:
1. Akademische Forschung
Forscher können den Workflow verwenden, um:
Umfassende Literaturreviews über mehrere Quellen durchzuführen
Schlüsselarbeiten und Forschungsergebnisse zu bestimmten Themen zu identifizieren
Verbindungen zwischen verschiedenen Forschungsbereichen zu entdecken
Über aktuelle Entwicklungen in ihrem Bereich informiert zu bleiben
Anpassung: Die Priorität der arXiv-Suche erhöhen und die Systemaufforderung anpassen, um akademische Zitiervorgaben zu betonen.
2. Marktforschung
Marktanalyse kann den Workflow nutzen, um:
Branchentrends und Marktdynamiken zu erforschen
Wettbewerbsstrategien und Positionierungen zu analysieren
Die finanzielle Leistung von Unternehmen und Sektoren zu überwachen
Nachrichten und Entwicklungen zu verfolgen, die spezifische Märkte betreffen
Anpassung: Yahoo Finance und Nachrichtenquellen priorisieren und die Systemaufforderung anpassen, um auf Geschäftsanalysen zu fokussieren.
3. Due Diligence
Investoren und juristische Fachkräfte können den Workflow nutzen für:
Umfassende Hintergrundüberprüfungen von Unternehmen und Einzelpersonen
Überprüfung von Ansprüchen und Aussagen
Identifikation potenzieller Risiken oder Probleme
Entdeckung von Verbindungen und Beziehungen
Anpassung: Fachspezifische Datenbanken hinzufügen und die Extraktionsfähigkeiten für spezifische Informationsarten verbessern.
4. Technische Dokumentation
Entwickler und technische Writer können von:
Umfassenden Informationen zu technischen Themen profitieren
Dokumentationen aus mehreren Quellen zusammenzustellen
Best-Practices und Lösungen für technische Herausforderungen zu identifizieren
Über neu auftauchende Technologien informiert zu bleiben
Anpassung: GitHub und technische Dokumentationsseiten als spezialisierte Werkzeuge hinzufügen und die Systemaufforderung anpassen, um Codebeispiele und technische Details zu priorisieren.
5. Inhaltsproduktion
Inhaltsproduzenten können den Workflow nutzen, um:
Themen gründlich zu recherchieren, bevor sie Inhalte erstellen
Vielfältige Perspektiven und Standpunkte zu sammeln
Faktische Genauigkeit mit der richtigen Quellenangabe sicherzustellen
Interessante Winkel und Erkenntnisse für ihre Inhalte zu identifizieren
Anpassung: Das Ausgabeformat an die Bedürfnisse der Inhaltserstellung anpassen und die Systemaufforderung verbessern, um ansprechende Präsentationen zu betonen.
Optimierung & Anpassung
Leistungsverbesserung
Forschungstiefe anpassen:
Erhöhen Sie
max_research_depthfür gründlichere Forschung (Standard: 7)Verringern für schnellere, aber weniger umfassende Ergebnisse
Beispiel:
"max_research_depth": 10für extrem gründliche Forschung
Inhaltsextraktion optimieren:
Passen Sie
content_char_limitan, um die Menge an Text zu steuern, die aus jeder Quelle extrahiert wirdStandard: 16000 Zeichen
Beispiel:
"content_char_limit": 8000für schnellere Verarbeitung mit weniger Kontext
URLs pro Suche konfigurieren:
Ändern Sie
urls_per_search, um zu steuern, wie viele URLs in jeder Iteration verarbeitet werdenStandard: 5 URLs
Beispiel:
"urls_per_search": 10für breitere Abdeckung in jeder Iteration
Modellparameter anpassen:
Temperatur basierend auf den Forschungsbedürfnissen optimieren (niedriger für sachliche Forschung, höher für kreative Erkundung)
max_tokens anpassen, um die Länge der Antworten zu steuern
Anpassung für spezifische Bereiche
Spezialisierte Forschungsagenten: Passen Sie die Systemaufforderung an, um bereichsspezifische Forschungsagenten zu erstellen:
Werkzeugpriorisierung: Passen Sie die Konfiguration an, um bereichsrelevante Werkzeuge zu priorisieren:
# For financial research financial_tools = ["YahooFinance", "FirecrawlExtractApi"]
Benutzerdefinierte Extraktionsschemata: Definieren Sie spezialisierte Extraktionsschemata für spezifische Informationsarten:
"schema": { "type": "object", "properties": { "companyName": {"type": "string"}, "revenue": {"type": "string"}, "growthRate": {"type": "string"}, "marketPosition": {"type": "string"} } }
Ausgabeformat-Anpassung: Passen Sie die Systemaufforderung an, um bereichs angemessene Ausgabeformate anzugeben:
Technische Einblicke
Architekturmuster
Der DeepResearch-Workflow veranschaulicht mehrere wichtige architektonische Muster:
Werkzeugorchestrierungsmuster:
Der Deep Research Agent fungiert als Orchestrator für eine Vielzahl von Werkzeugen
Jedes Werkzeug ist auf spezifische Informationen spezialisiert
Der Agent wählt dynamisch die geeigneten Werkzeuge basierend auf dem Forschungskontext aus und wendet sie an
Iteratives Verfeinerungsmuster:
Die Forschung erfolgt in mehreren Iterationen
Jede Iteration baut auf vorherigen Ergebnissen auf und adressiert identifizierte Wissenslücken
Der Prozess setzt sich fort, bis genügend Informationen gesammelt wurden oder die maximale Tiefe erreicht ist
Hierarchisches Verarbeitungsmuster:
Informationen werden durch progressive Abstraktionsstufen verarbeitet:
Rohe Inhalte → Strukturierte Daten → Schlüsselerkenntnisse → Umfassende Synthese
Jede Stufe transformiert die Daten in wertvollere und nutzbarere Formen
Innovative Ansätze
Der Workflow integriert mehrere innovative Ansätze für die Forschung:
Deep Research Algorithmus: Der Kernalgorithmus kombiniert iterative Erkundung mit systematischer Analyse:
async def deep_research(self, topic: str, max_depth: int = 7): state = { "findings": [], "summaries": [], "key_insights": [], "all_sources": [], "current_depth": 0, "max_depth": max_depth } while state["current_depth"] < state["max_depth"]: state["current_depth"] += 1 # SEARCH phase search_results = await self.search_web(query) # EXTRACT phase extracted_content = await self.extract_from_urls(search_results) state["findings"].extend(extracted_content) # ANALYZE phase analysis, raw_analysis = await self.analyze_and_plan(state["findings"], topic) # Update state with analysis results state["summaries"].append(raw_analysis) state["next_search_topic"] = analysis.get("next_search_topic", "") # Check if we should continue if not analysis.get("should_continue", False): break # Final synthesis final_analysis = await self.synthesize_findings(state["findings"], state["summaries"], topic) return { "analysis": final_analysis, "findings": state["findings"], "sources": state["all_sources"] }
Quellenverifizierung: Der Workflow implementiert einen ausgeklügelten Ansatz zur Verfolgung und Verifizierung von Quellen:
Jedes Informationsstück ist mit seiner Quelle verbunden
Quellen werden normalisiert, um Duplikate zu vermeiden
Die Domänenerfassung bietet zusätzlichen Kontext zur Autorität der Quelle
Die Quellenformatierung folgt konsistenten Zitationsstandards
Adaptive Werkzeugauswahl: Der Workflow wählt dynamisch die geeignetsten Werkzeuge basierend auf Mustern in den Werkzeugnamen und dem Forschungskontext aus:
# Tool selection strategy (simplified) tool_patterns = [ (lambda name: "tavily" in name.lower(), "Tavily Search"), (lambda name: "serp" in name.lower(), "Search Engine"), (lambda name: "wiki" in name.lower(), "Wikipedia Search"), (lambda name: "firecrawl" in name.lower(), "Firecrawl") ] for pattern_func, tool_type in tool_patterns: for tool in tools: if pattern_func(tool.name): return tool, tool_type
Fazit
Der DeepResearch-Workflow in PUNKU.AI stellt einen leistungsstarken Ansatz für KI-unterstützte Forschung dar, der die Denkfähigkeiten fortschrittlicher Sprachmodelle mit spezialisierten Werkzeugen für Informationsabfrage und -analyse kombiniert. Durch die Orchestrierung dieser Komponenten durch einen systematischen Forschungsprozess ermöglicht der Workflow eine umfassende Erkundung komplexer Themen über mehrere Quellen hinweg.
Die modulare Architektur des Workflows erlaubt Anpassungen an spezifische Bereiche und Anwendungsfälle, was ihn zu einer vielseitigen Lösung für Forscher, Analysten und Inhaltsproduzenten macht. Der Schwerpunkt auf Quellenangabe und strukturierter Präsentation stellt sicher, dass die Forschungsergebnisse nicht nur umfassend, sondern auch glaubwürdig und verwendbar sind.
Mit dem stetigen Fortschritt der KI-Technologie zeigen Workflows wie DeepResearch, wie visuelle Programmierumgebungen wie PUNKU.AI die Erstellung anspruchsvoller KI-Anwendungen vereinfachen können, sodass fortschrittliche Fähigkeiten einem breiteren Nutzerkreis zugänglich werden, ohne dass tiefgehende technische Expertise erforderlich ist.
Durch die Nutzung der Leistung von Claude, der Firecrawl-Web-Browsing-Funktionen und spezialisierter Wissensquellen stellt DeepResearch einen bedeutenden Schritt nach vorn dar, wie wir die Informationsentdeckung und -synthese im Zeitalter der KI angehen.
Erstellung eines leistungsstarken KI-Forschungsassistenten mit PUNKU.AIs DeepResearch-Workflow
TL;DR: Der DeepResearch-Workflow in PUNKU.AI integriert Claude mit leistungsstarken Web-Browsing-Funktionen, spezialisierten Wissenswerkzeugen und adaptiven Suchstrategien, um einen umfassenden Forschungsassistenten zu schaffen. Mit Firecrawl für die Web-Erkundung, zusammen mit Wikipedia, Wikidata, arXiv und Yahoo Finance, liefert dieser Workflow detaillierte, quellenbasierte Forschung zu jedem Thema.
Einleitung
In der informationsreichen Welt von heute erfordert gründliche Forschung das Navigieren durch riesige Datenmengen aus mehreren Quellen. Traditionelle Forschungsmethoden sind oft nicht effizient und umfassend. Der DeepResearch-Workflow von PUNKU.AI geht dieser Herausforderung nach, indem er einen KI-gestützten Forschungsassistenten schafft, der ausgeklügelte Web-Browsing-Funktionen mit Zugang zu spezialisierten Wissensquellen kombiniert.
Dieser Blogbeitrag wird erkunden, wie der DeepResearch-Workflow aufgebaut ist, seine Komponenten untersuchen und demonstrieren, wie er für umfassende Forschungsaufgaben genutzt werden kann. Wir werden in die technische Architektur eintauchen, die diesen Workflow antreibt, und zeigen, wie PUNKU.AIs visuelle Programmieransätze die Erstellung komplexer KI-Anwendungen vereinfachen.
Visuelle Darstellung des Workflows
Das obige Diagramm veranschaulicht die Struktur des DeepResearch-Workflows, wobei der Deep Research Agent im Mittelpunkt verschiedene Werkzeuge orchestriert, um Benutzeranfragen zu verarbeiten und umfassende Forschungsergebnisse zu liefern.
Komponentenaufgliederung
Kernkomponenten
1. Deep Research Agent
Der Deep Research Agent ist der zentrale Koordinator des Workflows und wird von Claude (Anthropic) angetrieben, mit spezieller Konfiguration zur Bewältigung von Forschungsaufgaben.
"model_name": "claude-3-7-sonnet-20250219", "temperature": 0.1, "max_tokens": 5000, "max_iterations": 40
Dieser Agent orchestriert den Forschungsprozess, indem er:
Komplexe Fragen in kleinere, erforschbare Komponenten zerlegt
Die geeigneten Werkzeuge für jede Forschungsaufgabe auswählt
Den iterativen Forschungsprozess mit konfigurierbarer Tiefe verwaltet (Standard: 7 Iterationen)
Ergebnisse in umfassende, gut strukturierte Antworten synthetisiert
Die richtige Quellenangabe für alle Informationen bereitstellt
2. Chat-Eingabe- und Ausgabe-Komponenten
Chat-Eingabe: Nimmt Benutzeranfragen entgegen und leitet sie an den Forschungsagenten weiter
Chat-Ausgabe: Zeigt formatierte Ergebnisse dem Benutzer an, einschließlich aller Quellen
3. Systemaufforderung
Die Systemaufforderung gibt dem Agenten detaillierte Anweisungen, wie er Forschung durchführen, Quellen bewerten und Antworten formatieren soll:
Web-Erkundungswerkzeuge
1. Tavily AI-Suche
Diese Komponente bietet eine KI-optimierte Suchmaschine, die speziell für LLMs und RAG-Anwendungen entwickelt wurde:
Unterstützt grundlegende und erweiterte Suchtiefe
Konfigurierbares Ergebnisslimit und Zeitrahmen
Option, Bilder und Zusammenfassungsantworten einzuschließen
Strukturierte Ausgabe mit URLs, Titeln und Inhalten
2. Firecrawl-Komponenten
Der Workflow umfasst vier spezialisierte Firecrawl-Komponenten, die zusammenarbeiten, um umfassende Web-Browsing-Funktionen bereitzustellen:
FirecrawlMapApi: Kartiert die Website-Struktur, um relevante Seiten zu identifizieren
Erstellt Standortkarten für systematisches Navigieren
Identifiziert Inhaltsbeziehungen innerhalb von Domänen
Unterstützt Sitemap- und Subdomain-Erkundungsoptionen
FirecrawlCrawlApi: Durchsucht gesamte Websites für umfassende Inhaltsuntersuchungen
Folgt Links bis zur festgelegten Tiefe
Verarbeitet Crawler-Optionen wie Tiefe und Linkverfolgung
Konfigurierbare Timeout-Einstellungen (Standard: 3000 ms)
FirecrawlScrapeApi: Extrahiert Inhalte von bestimmten URLs
Ruft saubere, strukturierte Inhalte von Webseiten ab
Formatiert die Ausgabe als Markdown für konsistente Präsentation
Konzentriert sich auf den Hauptinhalt und filtert Navigationselemente und Anzeigen
FirecrawlExtractApi: Führt gezielte Extraktionen spezifischer Informationen durch
Extrahiert strukturierte Informationen mithilfe von Schemata
Verwendet Eingabeaufforderungen in natürlicher Sprache zur Anleitung der Extraktion
Unterstützt die Integration von Websuchen für zusätzlichen Kontext
Wissensdatenbank-Werkzeuge
1. Wikipedia-Komponente
Bietet Enzyklopädie-Wissen zu einer breiten Palette von Themen:
"lang": "en", "k": 4, "doc_content_chars_max": 4000
Konfigurierbare Sprachenauswahl (Standard: Englisch)
Anpassbare Ergebnismenge (Standard: 4 Artikel)
Inhaltslängenverwaltung mit Zeichenlimits
Gibt sowohl strukturierte Daten als auch formatierten Text zurück
2. Wikidata-Komponente
Greift auf strukturierte Daten über Entitäten und Konzepte zu:
Gibt Entitätsinformationen mit Bezeichnungen, Beschreibungen und Identifikatoren zurück
Bietet eindeutige Entitäts-IDs (Q-Nummern) für zuverlässige Referenzen
Beinhaltet Konzept-URIs und Wikidata-Seiten-URLs
Nützlich zur Identifizierung spezifischer Entitäten und ihrer Eigenschaften
Spezialisierte Forschungswerkzeuge
1. arXiv-Komponente
Durchsucht und ruft akademische Forschungsarbeiten ab:
"search_type": "all", "max_results": 10
Durchsucht Arbeiten nach Titel, Abstract, Autor oder Kategorie
Gibt umfassende Metadaten, einschließlich Abstracts, Autoren und Veröffentlichungsdaten, zurück
Bietet direkte Links zu PDF-Downloads und Zeitschriftenreferenzen
Konfigurierbares Ergebnisslimit (Standard: 10 Arbeiten)
2. Yahoo Finance-Komponente
Greift auf Finanzdaten und Marktinformationsressourcen zu:
"method": "get_news", "num_news": 5
Ruft Aktienkurse mit verschiedenen Methoden ab (Informationen, Nachrichten, Finanzberichte)
Unterstützt über 25 Methoden zur Datenabfrage, einschließlich Gewinnberichte, Dividenden und SEC-Einreichungen
Konfigurierbare Anzahl von Nachrichtenartikeln für die Nachrichtenabfrage
Strukturierte Ausgabe mit Titeln, Links und Inhalten
Workflow-Erklärung
Schritt-für-Schritt-Ausführungsfluss
Benutzereingabeverarbeitung:
Der Workflow beginnt, wenn ein Benutzer eine Forschungsfrage über die Chat-Eingabe-Komponente einreicht
Die Anfrage wird zusammen mit der Systemaufforderung und den verfügbaren Werkzeugen an den Deep Research Agenten übergeben
Forschungsplanung:
Der Agent analysiert die Anfrage und zerlegt sie in spezifische Forschungsbestandteile
Er bestimmt eine geeignete Forschungsstrategie, einschließlich der zu verwendenden Werkzeuge und deren Reihenfolge
Iterativer Forschungsprozess:
Der Agent führt die Forschung in mehreren Iterationen durch (konfigurierbare Tiefe)
Für jede Iteration folgt er einem systematischen Prozess:
SUCHE-Phase: Verwendet die geeigneten Suchwerkzeuge (Tavily, Firecrawl), um relevante Quellen zu finden
EXTRAKT-Phase: Extrahiert Inhalte aus identifizierten Quellen
ANALYSE-Phase: Analysiert die gesammelten Informationen und identifiziert Wissenslücken
PLAN-Phase: Bestimmt den nächsten Suchfokus basierend auf der Analyse
Informationssynthese:
Nach Abschluss der Forschungsiterationen synthetisiert der Agent alle Ergebnisse
Er organisiert die Informationen logisch und erstellt eine umfassende Antwort
Alle Quellen werden ordnungsgemäß mit URLs angegeben
Antwortgenerierung:
Die endgültigen Forschungsergebnisse werden mit klarer Struktur und Überschriften formatiert
Quellen werden in einem speziellen Abschnitt mit dem richtigen Zitationsformat angegeben
Die Antwort wird dem Benutzer über die Chat-Ausgabe-Komponente angezeigt
Datenumwandlungen
Der Workflow führt mehrere wichtige Datenumwandlungen durch:
Abfrage → Suchergebnisse:
Benutzeranfragen werden in mehrere Suchanfragen über verschiedene Werkzeuge umgewandelt
Suchergebnisse werden als strukturierte Daten mit URLs und Metadaten zurückgegeben
URLs → Inhalt:
URLs aus den Suchergebnissen werden verwendet, um vollständige Inhalte zu extrahieren
Inhalte werden bereinigt, formatiert und zum Analysieren strukturiert
Inhalt → Erkenntnisse:
Rohinhalte werden analysiert, um wichtige Fakten, Datenpunkte und Konzepte zu extrahieren
Die Analyse identifiziert Muster, Beziehungen und Wissenslücken
Erkenntnisse → Umfassende Antwort:
Einzelne Erkenntnisse werden in eine kohärente, umfassende Antwort synthetisiert
Informationen werden mit klarer Struktur und logischem Fluss organisiert
Alle Quellen werden ordnungsgemäß angegeben
Schlüsselmechanismen
1. Adaptive Suchstrategie
Der DeepResearch-Workflow verwendet eine adaptive Suchstrategie, die die geeignetsten Werkzeuge basierend auf dem Forschungsthema auswählt und den Suchfokus iterativ verfeinert:
# Simplified logic for tool selection if topic_is_academic: primary_tool = "arXiv" elif topic_is_financial: primary_tool = "YahooFinance" else: primary_tool = "TavilySearch"
2. Quellenverfolgung
Der Workflow führt eine sorgfältige Verfolgung aller Quellen, um sicherzustellen, dass jedes Informationsstück auf seinen Ursprung zurückverfolgt werden kann:
# Source tracking mechanism (simplified) for content in extracted_content: source_url = content.get("source") if source_url and source_url not in state["all_sources"]: state["all_sources"].append(source_url)
3. Deep Research Loop
Der iterative Forschungsprozess wird durch eine strukturierte Schleife verwaltet, die fortgesetzt wird, bis ausreichend Informationen gesammelt sind oder die maximale Tiefe erreicht ist:
# Deep research loop (simplified) while state["current_depth"] < state["max_depth"]: state["current_depth"] += 1 search_results = await search_web(query) extracted_content = await extract_from_urls(search_results) analysis = await analyze_and_plan(extracted_content) if not analysis["should_continue"]: break query = analysis["next_search_topic"]
Anwendungsfälle & Anwendungen
Der DeepResearch-Workflow kann auf eine Vielzahl von Forschungsszenarien angewendet werden:
1. Akademische Forschung
Forscher können den Workflow verwenden, um:
Umfassende Literaturreviews über mehrere Quellen durchzuführen
Schlüsselarbeiten und Forschungsergebnisse zu bestimmten Themen zu identifizieren
Verbindungen zwischen verschiedenen Forschungsbereichen zu entdecken
Über aktuelle Entwicklungen in ihrem Bereich informiert zu bleiben
Anpassung: Die Priorität der arXiv-Suche erhöhen und die Systemaufforderung anpassen, um akademische Zitiervorgaben zu betonen.
2. Marktforschung
Marktanalyse kann den Workflow nutzen, um:
Branchentrends und Marktdynamiken zu erforschen
Wettbewerbsstrategien und Positionierungen zu analysieren
Die finanzielle Leistung von Unternehmen und Sektoren zu überwachen
Nachrichten und Entwicklungen zu verfolgen, die spezifische Märkte betreffen
Anpassung: Yahoo Finance und Nachrichtenquellen priorisieren und die Systemaufforderung anpassen, um auf Geschäftsanalysen zu fokussieren.
3. Due Diligence
Investoren und juristische Fachkräfte können den Workflow nutzen für:
Umfassende Hintergrundüberprüfungen von Unternehmen und Einzelpersonen
Überprüfung von Ansprüchen und Aussagen
Identifikation potenzieller Risiken oder Probleme
Entdeckung von Verbindungen und Beziehungen
Anpassung: Fachspezifische Datenbanken hinzufügen und die Extraktionsfähigkeiten für spezifische Informationsarten verbessern.
4. Technische Dokumentation
Entwickler und technische Writer können von:
Umfassenden Informationen zu technischen Themen profitieren
Dokumentationen aus mehreren Quellen zusammenzustellen
Best-Practices und Lösungen für technische Herausforderungen zu identifizieren
Über neu auftauchende Technologien informiert zu bleiben
Anpassung: GitHub und technische Dokumentationsseiten als spezialisierte Werkzeuge hinzufügen und die Systemaufforderung anpassen, um Codebeispiele und technische Details zu priorisieren.
5. Inhaltsproduktion
Inhaltsproduzenten können den Workflow nutzen, um:
Themen gründlich zu recherchieren, bevor sie Inhalte erstellen
Vielfältige Perspektiven und Standpunkte zu sammeln
Faktische Genauigkeit mit der richtigen Quellenangabe sicherzustellen
Interessante Winkel und Erkenntnisse für ihre Inhalte zu identifizieren
Anpassung: Das Ausgabeformat an die Bedürfnisse der Inhaltserstellung anpassen und die Systemaufforderung verbessern, um ansprechende Präsentationen zu betonen.
Optimierung & Anpassung
Leistungsverbesserung
Forschungstiefe anpassen:
Erhöhen Sie
max_research_depthfür gründlichere Forschung (Standard: 7)Verringern für schnellere, aber weniger umfassende Ergebnisse
Beispiel:
"max_research_depth": 10für extrem gründliche Forschung
Inhaltsextraktion optimieren:
Passen Sie
content_char_limitan, um die Menge an Text zu steuern, die aus jeder Quelle extrahiert wirdStandard: 16000 Zeichen
Beispiel:
"content_char_limit": 8000für schnellere Verarbeitung mit weniger Kontext
URLs pro Suche konfigurieren:
Ändern Sie
urls_per_search, um zu steuern, wie viele URLs in jeder Iteration verarbeitet werdenStandard: 5 URLs
Beispiel:
"urls_per_search": 10für breitere Abdeckung in jeder Iteration
Modellparameter anpassen:
Temperatur basierend auf den Forschungsbedürfnissen optimieren (niedriger für sachliche Forschung, höher für kreative Erkundung)
max_tokens anpassen, um die Länge der Antworten zu steuern
Anpassung für spezifische Bereiche
Spezialisierte Forschungsagenten: Passen Sie die Systemaufforderung an, um bereichsspezifische Forschungsagenten zu erstellen:
Werkzeugpriorisierung: Passen Sie die Konfiguration an, um bereichsrelevante Werkzeuge zu priorisieren:
# For financial research financial_tools = ["YahooFinance", "FirecrawlExtractApi"]
Benutzerdefinierte Extraktionsschemata: Definieren Sie spezialisierte Extraktionsschemata für spezifische Informationsarten:
"schema": { "type": "object", "properties": { "companyName": {"type": "string"}, "revenue": {"type": "string"}, "growthRate": {"type": "string"}, "marketPosition": {"type": "string"} } }
Ausgabeformat-Anpassung: Passen Sie die Systemaufforderung an, um bereichs angemessene Ausgabeformate anzugeben:
Technische Einblicke
Architekturmuster
Der DeepResearch-Workflow veranschaulicht mehrere wichtige architektonische Muster:
Werkzeugorchestrierungsmuster:
Der Deep Research Agent fungiert als Orchestrator für eine Vielzahl von Werkzeugen
Jedes Werkzeug ist auf spezifische Informationen spezialisiert
Der Agent wählt dynamisch die geeigneten Werkzeuge basierend auf dem Forschungskontext aus und wendet sie an
Iteratives Verfeinerungsmuster:
Die Forschung erfolgt in mehreren Iterationen
Jede Iteration baut auf vorherigen Ergebnissen auf und adressiert identifizierte Wissenslücken
Der Prozess setzt sich fort, bis genügend Informationen gesammelt wurden oder die maximale Tiefe erreicht ist
Hierarchisches Verarbeitungsmuster:
Informationen werden durch progressive Abstraktionsstufen verarbeitet:
Rohe Inhalte → Strukturierte Daten → Schlüsselerkenntnisse → Umfassende Synthese
Jede Stufe transformiert die Daten in wertvollere und nutzbarere Formen
Innovative Ansätze
Der Workflow integriert mehrere innovative Ansätze für die Forschung:
Deep Research Algorithmus: Der Kernalgorithmus kombiniert iterative Erkundung mit systematischer Analyse:
async def deep_research(self, topic: str, max_depth: int = 7): state = { "findings": [], "summaries": [], "key_insights": [], "all_sources": [], "current_depth": 0, "max_depth": max_depth } while state["current_depth"] < state["max_depth"]: state["current_depth"] += 1 # SEARCH phase search_results = await self.search_web(query) # EXTRACT phase extracted_content = await self.extract_from_urls(search_results) state["findings"].extend(extracted_content) # ANALYZE phase analysis, raw_analysis = await self.analyze_and_plan(state["findings"], topic) # Update state with analysis results state["summaries"].append(raw_analysis) state["next_search_topic"] = analysis.get("next_search_topic", "") # Check if we should continue if not analysis.get("should_continue", False): break # Final synthesis final_analysis = await self.synthesize_findings(state["findings"], state["summaries"], topic) return { "analysis": final_analysis, "findings": state["findings"], "sources": state["all_sources"] }
Quellenverifizierung: Der Workflow implementiert einen ausgeklügelten Ansatz zur Verfolgung und Verifizierung von Quellen:
Jedes Informationsstück ist mit seiner Quelle verbunden
Quellen werden normalisiert, um Duplikate zu vermeiden
Die Domänenerfassung bietet zusätzlichen Kontext zur Autorität der Quelle
Die Quellenformatierung folgt konsistenten Zitationsstandards
Adaptive Werkzeugauswahl: Der Workflow wählt dynamisch die geeignetsten Werkzeuge basierend auf Mustern in den Werkzeugnamen und dem Forschungskontext aus:
# Tool selection strategy (simplified) tool_patterns = [ (lambda name: "tavily" in name.lower(), "Tavily Search"), (lambda name: "serp" in name.lower(), "Search Engine"), (lambda name: "wiki" in name.lower(), "Wikipedia Search"), (lambda name: "firecrawl" in name.lower(), "Firecrawl") ] for pattern_func, tool_type in tool_patterns: for tool in tools: if pattern_func(tool.name): return tool, tool_type
Fazit
Der DeepResearch-Workflow in PUNKU.AI stellt einen leistungsstarken Ansatz für KI-unterstützte Forschung dar, der die Denkfähigkeiten fortschrittlicher Sprachmodelle mit spezialisierten Werkzeugen für Informationsabfrage und -analyse kombiniert. Durch die Orchestrierung dieser Komponenten durch einen systematischen Forschungsprozess ermöglicht der Workflow eine umfassende Erkundung komplexer Themen über mehrere Quellen hinweg.
Die modulare Architektur des Workflows erlaubt Anpassungen an spezifische Bereiche und Anwendungsfälle, was ihn zu einer vielseitigen Lösung für Forscher, Analysten und Inhaltsproduzenten macht. Der Schwerpunkt auf Quellenangabe und strukturierter Präsentation stellt sicher, dass die Forschungsergebnisse nicht nur umfassend, sondern auch glaubwürdig und verwendbar sind.
Mit dem stetigen Fortschritt der KI-Technologie zeigen Workflows wie DeepResearch, wie visuelle Programmierumgebungen wie PUNKU.AI die Erstellung anspruchsvoller KI-Anwendungen vereinfachen können, sodass fortschrittliche Fähigkeiten einem breiteren Nutzerkreis zugänglich werden, ohne dass tiefgehende technische Expertise erforderlich ist.
Durch die Nutzung der Leistung von Claude, der Firecrawl-Web-Browsing-Funktionen und spezialisierter Wissensquellen stellt DeepResearch einen bedeutenden Schritt nach vorn dar, wie wir die Informationsentdeckung und -synthese im Zeitalter der KI angehen.

Intelligente Web-Erkundung
✅ Entdeckt und kartiert automatisch gesamte Site-Strukturen
✅ Zieht saubere, relevante Inhalte von jeder Webseite
✅ Folgt Links und erkundet verwandte Inhalte systematisch
✅ Greift auf die neuesten Informationen von aktiven Websites zu
Intelligente Web-Erkundung
✅ Entdeckt und kartiert automatisch gesamte Site-Strukturen
✅ Zieht saubere, relevante Inhalte von jeder Webseite
✅ Folgt Links und erkundet verwandte Inhalte systematisch
✅ Greift auf die neuesten Informationen von aktiven Websites zu
Von Komplexität zu Klarheit
✅ Kombiniert Informationen aus Dutzenden von Quellen zu kohärenten Erkenntnissen
✅ Ausgereifter Inhalt, bereit für Berichte, Präsentationen oder Veröffentlichungen
Jetzt starten
Von Komplexität zu Klarheit
✅ Kombiniert Informationen aus Dutzenden von Quellen zu kohärenten Erkenntnissen
✅ Ausgereifter Inhalt, bereit für Berichte, Präsentationen oder Veröffentlichungen
Jetzt starten
