01.04.2025
01.04.2025
Chat für alle: Erstellung einer universellen LLM-Chatoberfläche mit PUNKU.AI
Chat für alle: Erstellung einer universellen LLM-Chatoberfläche mit PUNKU.AI

Chat für Alle: Aufbau einer universellen LLM-Chat-Schnittstelle mit PUNKU.AI
Zugriff auf über 200 hochmoderne Sprachmodelle über eine einzige Konversationsschnittstelle
TL;DR
Der PUNKU.AI Chat für Alle Workflow bietet eine flexible Chatbot-Implementierung, die es Ihnen ermöglicht, über eine einzige Schnittstelle mit über 200 verschiedenen KI-Modellen zu interagieren. Er bietet Gedächtnis für Konversationen, Systemaufforderungen und die Möglichkeit zum Hochladen von Dateien, was ihn zu einer leistungsstarken Grundlage für den Aufbau benutzerdefinierter Chat-Erlebnisse über mehrere LLM-Anbieter hinweg macht.
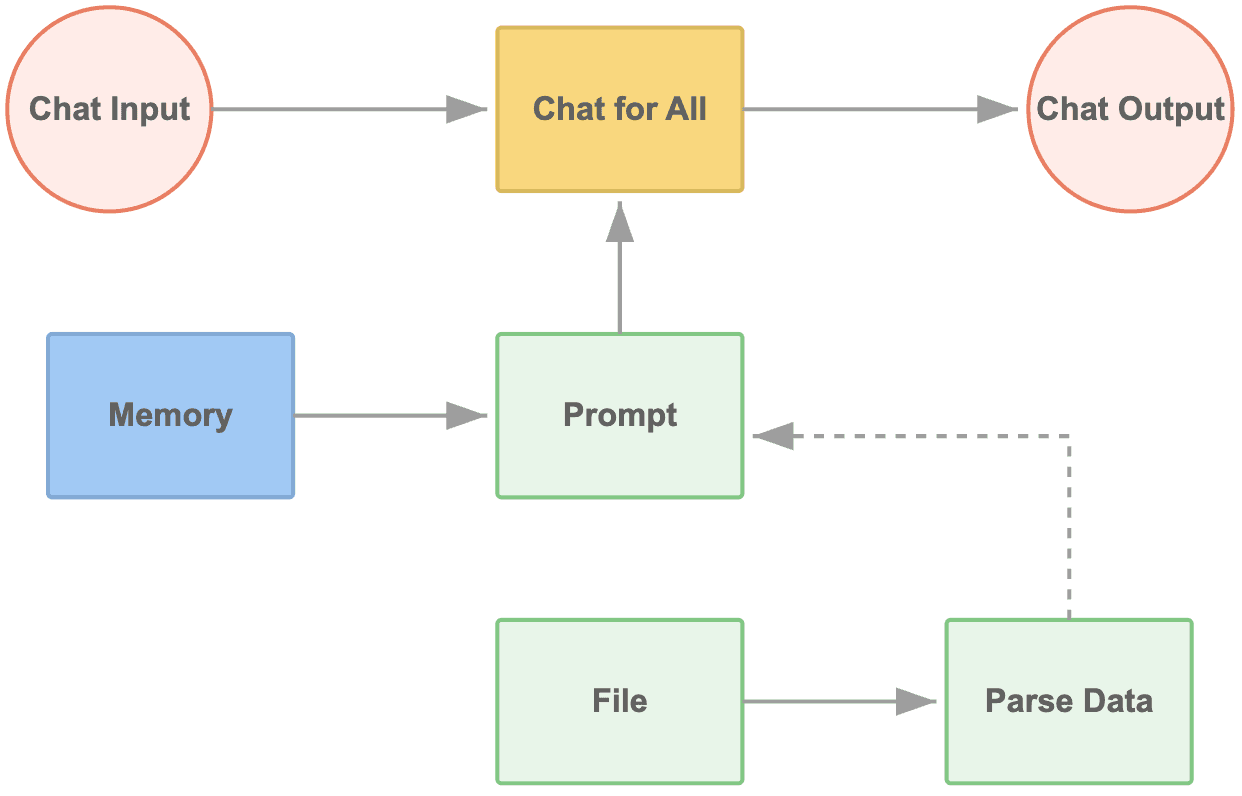
Diagramm: Grundfluss des Chat für Alle Workflows, das zeigt, wie Benutzereingaben, Systemaufforderungen, Gedächtnis und Dateien durch die LLM-Komponente verarbeitet werden, um Antworten zu generieren.
Einführung
In der sich schnell entwickelnden KI-Landschaft von heute ist der Zugriff auf verschiedene große Sprachmodelle (LLMs) und deren Vergleich für Entwickler und Organisationen zunehmend wichtig geworden. Der "Chat für Alle" Workflow in PUNKU.AI begegnet diesem Bedarf, indem er eine einheitliche Schnittstelle bereitstellt, um mit über 200 verschiedenen KI-Modellen zu interagieren, darunter Modelle von OpenAI, Anthropic, Meta und anderen.
Dieser Blogbeitrag führt Sie durch die Struktur und Funktionalität des Chat für Alle Workflows, erklärt, wie jede Komponente zusammenarbeitet, und demonstriert, wie Sie dieses flexible System nutzen können, um leistungsstarke Konversationsanwendungen mit minimalem Aufwand zu erstellen.
Komponentenübersicht
Werfen wir einen Blick auf jede wichtige Komponente im Chat für Alle Workflow und verstehen wir deren Rolle in der Gesamtarchitektur.
Chat-Eingabekomponente
Die Chat-Eingabekomponente dient als primäres Benutzeroberflächenelement, in dem Nachrichten eingegeben werden.
Die Chat-Eingabekomponente erfasst Benutzeranfragen und leitet sie an die Hauptverarbeitungskomponente weiter. Sie fungiert als Einstiegspunkt für alle Benutzerinteraktionen und kann angepasst werden, um zu ändern, wie Nachrichten in der Schnittstelle angezeigt werden.
Gedächtnis-Komponente
Die Gedächtnis-Komponente ist verantwortlich für die Aufrechterhaltung der Gesprächshistorie und des Kontexts über mehrere Nachrichten hinweg.
Diese Komponente ist entscheidend für die Aufrechterhaltung des Kontexts in Gesprächen. Sie ruft gespeicherte Nachrichten aus der Datenbank von PUNKU.AI ab und formatiert sie für die Einbeziehung in die Aufforderung, die an das Sprachmodell gesendet wird. Die Gedächtnis-Komponente unterstützt das Filtern nach Absenderart und ermöglicht eine anpassbare Formatierung historischer Nachrichten.
Prompt-Komponente
Die Prompt-Komponente strukturiert die Informationen, die an das Sprachmodell gesendet werden, indem sie die Systemanweisungen, die Gesprächshistorie und die Benutzereingaben kombiniert.
Die Prompt-Vorlage enthält Platzhalter für dynamische Inhalte: {memory} für die Gesprächshistorie und {content} für hochgeladene Dateien. Diese Komponente definiert das Verhalten und die Fähigkeiten der KI, indem sie den Kontext für das Gespräch festlegt.
Chat für Alle Komponente
Dies ist die Hauptkomponente, die mit verschiedenen LLM-Anbietern und Modellen kommuniziert.
Die Chat für Alle-Komponente verwaltet die tatsächliche LLM-Interaktion und unterstützt Modelle von mehreren Anbietern, darunter OpenAI, Anthropic (Claude) und Metas Llama-Modelle. Sie verwaltet API-Verbindungen, modell-spezifische Parameter und die Streaming-Antwort.
Datei- und Datenverarbeitungskomponenten
Diese Komponenten ermöglichen das Hochladen und Verarbeiten von Dateien.
Die Dateikomponente lädt externe Dateien, während die Datenverarbeitungskomponente den Dateihalt in ein Format umwandelt, das in die Aufforderung aufgenommen werden kann. Dadurch können Benutzer Dokumente hochladen, auf die die KI bei der Generierung von Antworten verweisen kann.
Chat-Ausgabekomponente
Die Chat-Ausgabekomponente zeigt die Antwort der KI in der Chat-Oberfläche an.
Diese Komponente verwaltet die Anzeige der von der KI generierten Antworten und bestimmt, wie sie in der Gesprächshistorie gespeichert werden.
Workflow-Erklärung
Gehen wir den schrittweisen Prozess durch, wie der Chat für Alle-Workflow funktioniert:
Benutzereingabe sammeln: Der Benutzer gibt eine Nachricht über die Chat-Eingabekomponente ein.
Gedächtnis abrufen: Die Gedächtnis-Komponente ruft vorherige Nachrichten aus der Gesprächshistorie ab.
Prompt-Bildung: Die Prompt-Komponente kombiniert die Systemanweisungen, die Gesprächshistorie aus dem Gedächtnis und eventuelle hochgeladene Dateiinhalte aus der Datenverarbeitung zu einer strukturierten Aufforderung.
Modellauswahl und Verarbeitung: Die Chat für Alle-Komponente sendet die zusammengestellte Aufforderung an das ausgewählte Sprachmodell und verwaltet die API-Interaktion.
Antwortgenerierung: Das Sprachmodell verarbeitet die Eingabe und generiert eine Antwort.
Ausgabe anzeigen: Die Chat-Ausgabekomponente zeigt die Antwort des Modells dem Benutzer an und speichert sie in der Gesprächshistorie.
Fortsetzung der Schleife: Der Prozess wiederholt sich für jede neue Benutzernachricht, wobei die aktualisierte Gesprächshistorie in den nachfolgenden Aufforderungen enthalten ist.
Der Workflow erhält den Sitzungsstatus während des gesamten Gesprächs und stellt sicher, dass der Kontext erhalten bleibt und das Modell auf frühere Beiträge verweisen kann, wenn es Antworten generiert.
Anwendungsfälle & Anwendungen
Die Flexibilität des Chat für Alle Workflows macht ihn für eine Vielzahl von Anwendungen geeignet:
1. Modellvergleich und -bewertung
Testen Sie dieselben Aufforderungen über verschiedene Modelle hinweg, um Qualität, Stil und Leistung für spezifische Aufgaben zu vergleichen. Dies ist von unschätzbarem Wert, um das am besten geeignete Modell für Ihren spezifischen Anwendungsfall auszuwählen.
2. Benutzerdefinierte Wissensdatenbank-Assistenten
Laden Sie branchenspezifische Dokumente hoch und erstellen Sie spezialisierte Assistenten, die diese Informationen bei der Beantwortung von Anfragen berücksichtigen können. Ideal für die Erstellung von Dokumentationshelfern, Forschungsassistenten oder Kundenservicerobots.
3. Mehrere Konversationsanwendungen
Bauen Sie Anwendungen, die den Kontext über mehrere Austausche hinweg aufrechterhalten, wie Tutoriansysteme, Therapieassistenten oder Interview-Simulatoren, die frühere Teile des Gesprächs berücksichtigen müssen.
4. Inhalte-Generierungs-Workflows
Erstellen Sie Systeme zur Generierung von Marketingtexten, Produktbeschreibungen oder kreativen Inhalten mit der Fähigkeit, Ausgaben iterativ durch Gespräche zu verfeinern.
5. Bildungstools
Entwickeln Sie interaktive Lernumgebungen, in denen Schüler in tiefgreifende, kontextuelle Gespräche über komplexe Themen mit Feedback und Anleitung eintauchen können.
Optimierung & Anpassung
Hier sind einige Möglichkeiten, wie Sie den Chat für Alle Workflow anpassen und verbessern können:
Modellauswahl-Optimierung
Unterschiedliche Aufgaben funktionieren am besten mit verschiedenen Modellen. Beachten Sie diese Richtlinien:
Für kreative Aufgaben: Versuchen Sie Claude Opus oder GPT-4
Für faktische Q&A: Llama 3 70B oder Claude Sonnet schneiden gut ab
Für Codegenerierung: Verwenden Sie Anthropics Claude Opus oder Code Llama
Für Effizienz und Geschwindigkeit: Kleinere Modelle wie Llama 3 8B bieten oft schnellere Antworten
Gedächtnisverwaltung
Passen Sie die Gedächtniseinstellungen je nach Bedarf an:
Erhöhen Sie
n_messagesfür Anwendungen mit längerem KontextVerringern Sie es für Anwendungen, bei denen der aktuelle Kontext wichtiger ist
Ändern Sie die Vorlage, um Zeitstempel oder Rollen für eine strukturierte Historie einzufügen
Systemaufforderung verfeinern
Die Systemaufforderung hat einen erheblichen Einfluss auf das Verhalten des Modells:
Dateiverarbeitungsverbesserung
Für komplexere Anwendungen:
Verbinden Sie mehrere Dateikomponenten, um verschiedene Eingabetypen zu verarbeiten
Fügen Sie spezialisierte Parsing-Komponenten für strukturierte Daten wie CSV oder JSON hinzu
Integrieren Sie Schritte zur Datenumwandlung für die Vorverarbeitung, bevor Sie sie dem Modell zuführen
Technische Insights
Der Chat für Alle Workflow verkörpert mehrere Architekturmodelle, die erwähnenswert sind:
Integration mehrerer LLM-Anbieter
Der Workflow abstrahiert die Unterschiede zwischen verschiedenen LLM-APIs durch eine einheitliche Schnittstelle. Dies wird erreicht durch:
Ein flexibles API-Schlüsselmanagementsystem
Modellspezifische Parameterverarbeitung
Dynamische Basis-URL-Konfiguration
Adaptive Antwortverarbeitung
Dieser Ansatz ermöglicht einen nahtlosen Wechsel zwischen Anbietern, ohne die Gesamtstruktur des Workflows zu ändern.
Statusverwaltungsmuster
Der Workflow implementiert ein robustes Statusverwaltungsmuster durch:
Sessionsbasiertes Verfolgen von Gesprächen
Persistente Gedächtnisspeicherung
Kontextbewahrung über Interaktionen hinweg
Dies gewährleistet Kontinuität und Kohärenz in mehrteiligen Gesprächen, was entscheidend ist, um die Illusion eines kohärenten "Geistes" hinter der Schnittstelle aufrechtzuerhalten.
Prompt-Engineering-Rahmen
Der Workflow integriert einen strukturierten Ansatz für das Prompt-Engineering:
Trennung von Systemanweisungen, Kontext und Benutzereingaben
Dynamisches Ausfüllen von Vorlagen basierend auf dem Gesprächszustand
Optionale Inhaltsintegration aus externen Quellen
Dieser geschichtete Ansatz zur Prompt-Konstruktion macht das System hochgradig anpassbar für verschiedene Anwendungsfälle, ohne dass strukturelle Änderungen erforderlich sind.
Optimierungsmöglichkeit: Der aktuelle Workflow könnte optimiert werden, indem eine Komponente für abrufgestützte Generierung (RAG) implementiert wird, um hochgeladene Dateien, insbesondere große Dokumente, die die Kontextfenster überschreiten könnten, effektiver zu nutzen.
Fazit
Der Chat für Alle Workflow in PUNKU.AI bietet eine leistungsstarke, flexible Grundlage für den Aufbau von Konversations-KI-Anwendungen mit Zugriff auf die größtmögliche Bandbreite an Sprachmodellen. Durch die Kombination einer durchdachten Komponentenarchitektur mit robustem Gedächtnismanagement und anpassbarem Prompting ermöglicht es Entwicklern, schnell komplexe Konversationserlebnisse zu prototypisieren und bereitzustellen.
Ob Sie nun die Modellleistung vergleichen, spezialisierte Assistenten erstellen oder interaktive Anwendungen gestalten, dieser Workflow bietet einen praktischen Ausgangspunkt, der an praktisch jeden Anwendungsfall für Konversations-KI angepasst werden kann.
Probieren Sie den Chat für Alle Workflow noch heute aus, um die Flexibilität der Interaktion mit über 200 KI-Modellen über eine einzige, einheitliche Schnittstelle zu erleben!
Wollen Sie mehr über den Aufbau von KI-Workflows mit PUNKU.AI erfahren? Sehen Sie sich unsere anderen Tutorials und Workflow-Vorlagen im PUNKU.AI-Marktplatz an.
Chat für Alle: Aufbau einer universellen LLM-Chat-Schnittstelle mit PUNKU.AI
Zugriff auf über 200 hochmoderne Sprachmodelle über eine einzige Konversationsschnittstelle
TL;DR
Der PUNKU.AI Chat für Alle Workflow bietet eine flexible Chatbot-Implementierung, die es Ihnen ermöglicht, über eine einzige Schnittstelle mit über 200 verschiedenen KI-Modellen zu interagieren. Er bietet Gedächtnis für Konversationen, Systemaufforderungen und die Möglichkeit zum Hochladen von Dateien, was ihn zu einer leistungsstarken Grundlage für den Aufbau benutzerdefinierter Chat-Erlebnisse über mehrere LLM-Anbieter hinweg macht.
Diagramm: Grundfluss des Chat für Alle Workflows, das zeigt, wie Benutzereingaben, Systemaufforderungen, Gedächtnis und Dateien durch die LLM-Komponente verarbeitet werden, um Antworten zu generieren.
Einführung
In der sich schnell entwickelnden KI-Landschaft von heute ist der Zugriff auf verschiedene große Sprachmodelle (LLMs) und deren Vergleich für Entwickler und Organisationen zunehmend wichtig geworden. Der "Chat für Alle" Workflow in PUNKU.AI begegnet diesem Bedarf, indem er eine einheitliche Schnittstelle bereitstellt, um mit über 200 verschiedenen KI-Modellen zu interagieren, darunter Modelle von OpenAI, Anthropic, Meta und anderen.
Dieser Blogbeitrag führt Sie durch die Struktur und Funktionalität des Chat für Alle Workflows, erklärt, wie jede Komponente zusammenarbeitet, und demonstriert, wie Sie dieses flexible System nutzen können, um leistungsstarke Konversationsanwendungen mit minimalem Aufwand zu erstellen.
Komponentenübersicht
Werfen wir einen Blick auf jede wichtige Komponente im Chat für Alle Workflow und verstehen wir deren Rolle in der Gesamtarchitektur.
Chat-Eingabekomponente
Die Chat-Eingabekomponente dient als primäres Benutzeroberflächenelement, in dem Nachrichten eingegeben werden.
Die Chat-Eingabekomponente erfasst Benutzeranfragen und leitet sie an die Hauptverarbeitungskomponente weiter. Sie fungiert als Einstiegspunkt für alle Benutzerinteraktionen und kann angepasst werden, um zu ändern, wie Nachrichten in der Schnittstelle angezeigt werden.
Gedächtnis-Komponente
Die Gedächtnis-Komponente ist verantwortlich für die Aufrechterhaltung der Gesprächshistorie und des Kontexts über mehrere Nachrichten hinweg.
Diese Komponente ist entscheidend für die Aufrechterhaltung des Kontexts in Gesprächen. Sie ruft gespeicherte Nachrichten aus der Datenbank von PUNKU.AI ab und formatiert sie für die Einbeziehung in die Aufforderung, die an das Sprachmodell gesendet wird. Die Gedächtnis-Komponente unterstützt das Filtern nach Absenderart und ermöglicht eine anpassbare Formatierung historischer Nachrichten.
Prompt-Komponente
Die Prompt-Komponente strukturiert die Informationen, die an das Sprachmodell gesendet werden, indem sie die Systemanweisungen, die Gesprächshistorie und die Benutzereingaben kombiniert.
Die Prompt-Vorlage enthält Platzhalter für dynamische Inhalte: {memory} für die Gesprächshistorie und {content} für hochgeladene Dateien. Diese Komponente definiert das Verhalten und die Fähigkeiten der KI, indem sie den Kontext für das Gespräch festlegt.
Chat für Alle Komponente
Dies ist die Hauptkomponente, die mit verschiedenen LLM-Anbietern und Modellen kommuniziert.
Die Chat für Alle-Komponente verwaltet die tatsächliche LLM-Interaktion und unterstützt Modelle von mehreren Anbietern, darunter OpenAI, Anthropic (Claude) und Metas Llama-Modelle. Sie verwaltet API-Verbindungen, modell-spezifische Parameter und die Streaming-Antwort.
Datei- und Datenverarbeitungskomponenten
Diese Komponenten ermöglichen das Hochladen und Verarbeiten von Dateien.
Die Dateikomponente lädt externe Dateien, während die Datenverarbeitungskomponente den Dateihalt in ein Format umwandelt, das in die Aufforderung aufgenommen werden kann. Dadurch können Benutzer Dokumente hochladen, auf die die KI bei der Generierung von Antworten verweisen kann.
Chat-Ausgabekomponente
Die Chat-Ausgabekomponente zeigt die Antwort der KI in der Chat-Oberfläche an.
Diese Komponente verwaltet die Anzeige der von der KI generierten Antworten und bestimmt, wie sie in der Gesprächshistorie gespeichert werden.
Workflow-Erklärung
Gehen wir den schrittweisen Prozess durch, wie der Chat für Alle-Workflow funktioniert:
Benutzereingabe sammeln: Der Benutzer gibt eine Nachricht über die Chat-Eingabekomponente ein.
Gedächtnis abrufen: Die Gedächtnis-Komponente ruft vorherige Nachrichten aus der Gesprächshistorie ab.
Prompt-Bildung: Die Prompt-Komponente kombiniert die Systemanweisungen, die Gesprächshistorie aus dem Gedächtnis und eventuelle hochgeladene Dateiinhalte aus der Datenverarbeitung zu einer strukturierten Aufforderung.
Modellauswahl und Verarbeitung: Die Chat für Alle-Komponente sendet die zusammengestellte Aufforderung an das ausgewählte Sprachmodell und verwaltet die API-Interaktion.
Antwortgenerierung: Das Sprachmodell verarbeitet die Eingabe und generiert eine Antwort.
Ausgabe anzeigen: Die Chat-Ausgabekomponente zeigt die Antwort des Modells dem Benutzer an und speichert sie in der Gesprächshistorie.
Fortsetzung der Schleife: Der Prozess wiederholt sich für jede neue Benutzernachricht, wobei die aktualisierte Gesprächshistorie in den nachfolgenden Aufforderungen enthalten ist.
Der Workflow erhält den Sitzungsstatus während des gesamten Gesprächs und stellt sicher, dass der Kontext erhalten bleibt und das Modell auf frühere Beiträge verweisen kann, wenn es Antworten generiert.
Anwendungsfälle & Anwendungen
Die Flexibilität des Chat für Alle Workflows macht ihn für eine Vielzahl von Anwendungen geeignet:
1. Modellvergleich und -bewertung
Testen Sie dieselben Aufforderungen über verschiedene Modelle hinweg, um Qualität, Stil und Leistung für spezifische Aufgaben zu vergleichen. Dies ist von unschätzbarem Wert, um das am besten geeignete Modell für Ihren spezifischen Anwendungsfall auszuwählen.
2. Benutzerdefinierte Wissensdatenbank-Assistenten
Laden Sie branchenspezifische Dokumente hoch und erstellen Sie spezialisierte Assistenten, die diese Informationen bei der Beantwortung von Anfragen berücksichtigen können. Ideal für die Erstellung von Dokumentationshelfern, Forschungsassistenten oder Kundenservicerobots.
3. Mehrere Konversationsanwendungen
Bauen Sie Anwendungen, die den Kontext über mehrere Austausche hinweg aufrechterhalten, wie Tutoriansysteme, Therapieassistenten oder Interview-Simulatoren, die frühere Teile des Gesprächs berücksichtigen müssen.
4. Inhalte-Generierungs-Workflows
Erstellen Sie Systeme zur Generierung von Marketingtexten, Produktbeschreibungen oder kreativen Inhalten mit der Fähigkeit, Ausgaben iterativ durch Gespräche zu verfeinern.
5. Bildungstools
Entwickeln Sie interaktive Lernumgebungen, in denen Schüler in tiefgreifende, kontextuelle Gespräche über komplexe Themen mit Feedback und Anleitung eintauchen können.
Optimierung & Anpassung
Hier sind einige Möglichkeiten, wie Sie den Chat für Alle Workflow anpassen und verbessern können:
Modellauswahl-Optimierung
Unterschiedliche Aufgaben funktionieren am besten mit verschiedenen Modellen. Beachten Sie diese Richtlinien:
Für kreative Aufgaben: Versuchen Sie Claude Opus oder GPT-4
Für faktische Q&A: Llama 3 70B oder Claude Sonnet schneiden gut ab
Für Codegenerierung: Verwenden Sie Anthropics Claude Opus oder Code Llama
Für Effizienz und Geschwindigkeit: Kleinere Modelle wie Llama 3 8B bieten oft schnellere Antworten
Gedächtnisverwaltung
Passen Sie die Gedächtniseinstellungen je nach Bedarf an:
Erhöhen Sie
n_messagesfür Anwendungen mit längerem KontextVerringern Sie es für Anwendungen, bei denen der aktuelle Kontext wichtiger ist
Ändern Sie die Vorlage, um Zeitstempel oder Rollen für eine strukturierte Historie einzufügen
Systemaufforderung verfeinern
Die Systemaufforderung hat einen erheblichen Einfluss auf das Verhalten des Modells:
Dateiverarbeitungsverbesserung
Für komplexere Anwendungen:
Verbinden Sie mehrere Dateikomponenten, um verschiedene Eingabetypen zu verarbeiten
Fügen Sie spezialisierte Parsing-Komponenten für strukturierte Daten wie CSV oder JSON hinzu
Integrieren Sie Schritte zur Datenumwandlung für die Vorverarbeitung, bevor Sie sie dem Modell zuführen
Technische Insights
Der Chat für Alle Workflow verkörpert mehrere Architekturmodelle, die erwähnenswert sind:
Integration mehrerer LLM-Anbieter
Der Workflow abstrahiert die Unterschiede zwischen verschiedenen LLM-APIs durch eine einheitliche Schnittstelle. Dies wird erreicht durch:
Ein flexibles API-Schlüsselmanagementsystem
Modellspezifische Parameterverarbeitung
Dynamische Basis-URL-Konfiguration
Adaptive Antwortverarbeitung
Dieser Ansatz ermöglicht einen nahtlosen Wechsel zwischen Anbietern, ohne die Gesamtstruktur des Workflows zu ändern.
Statusverwaltungsmuster
Der Workflow implementiert ein robustes Statusverwaltungsmuster durch:
Sessionsbasiertes Verfolgen von Gesprächen
Persistente Gedächtnisspeicherung
Kontextbewahrung über Interaktionen hinweg
Dies gewährleistet Kontinuität und Kohärenz in mehrteiligen Gesprächen, was entscheidend ist, um die Illusion eines kohärenten "Geistes" hinter der Schnittstelle aufrechtzuerhalten.
Prompt-Engineering-Rahmen
Der Workflow integriert einen strukturierten Ansatz für das Prompt-Engineering:
Trennung von Systemanweisungen, Kontext und Benutzereingaben
Dynamisches Ausfüllen von Vorlagen basierend auf dem Gesprächszustand
Optionale Inhaltsintegration aus externen Quellen
Dieser geschichtete Ansatz zur Prompt-Konstruktion macht das System hochgradig anpassbar für verschiedene Anwendungsfälle, ohne dass strukturelle Änderungen erforderlich sind.
Optimierungsmöglichkeit: Der aktuelle Workflow könnte optimiert werden, indem eine Komponente für abrufgestützte Generierung (RAG) implementiert wird, um hochgeladene Dateien, insbesondere große Dokumente, die die Kontextfenster überschreiten könnten, effektiver zu nutzen.
Fazit
Der Chat für Alle Workflow in PUNKU.AI bietet eine leistungsstarke, flexible Grundlage für den Aufbau von Konversations-KI-Anwendungen mit Zugriff auf die größtmögliche Bandbreite an Sprachmodellen. Durch die Kombination einer durchdachten Komponentenarchitektur mit robustem Gedächtnismanagement und anpassbarem Prompting ermöglicht es Entwicklern, schnell komplexe Konversationserlebnisse zu prototypisieren und bereitzustellen.
Ob Sie nun die Modellleistung vergleichen, spezialisierte Assistenten erstellen oder interaktive Anwendungen gestalten, dieser Workflow bietet einen praktischen Ausgangspunkt, der an praktisch jeden Anwendungsfall für Konversations-KI angepasst werden kann.
Probieren Sie den Chat für Alle Workflow noch heute aus, um die Flexibilität der Interaktion mit über 200 KI-Modellen über eine einzige, einheitliche Schnittstelle zu erleben!
Wollen Sie mehr über den Aufbau von KI-Workflows mit PUNKU.AI erfahren? Sehen Sie sich unsere anderen Tutorials und Workflow-Vorlagen im PUNKU.AI-Marktplatz an.

Smart Modellvergleich
✅ Vergleichen Sie GPT-4, Claude, Llama und über 200 weitere in Echtzeit
✅ Testen Sie die gleichen Eingaben über Modelle hinweg, um die beste Wahl zu finden
✅ Bewerten Sie die Genauigkeit, Kreativität und stilistischen Unterschiede der Antworten
✅ Identifizieren Sie, welche Modelle beim Programmieren, Schreiben, Analysieren oder bei Kreativität hervorstechen
Smart Modellvergleich
✅ Vergleichen Sie GPT-4, Claude, Llama und über 200 weitere in Echtzeit
✅ Testen Sie die gleichen Eingaben über Modelle hinweg, um die beste Wahl zu finden
✅ Bewerten Sie die Genauigkeit, Kreativität und stilistischen Unterschiede der Antworten
✅ Identifizieren Sie, welche Modelle beim Programmieren, Schreiben, Analysieren oder bei Kreativität hervorstechen
Universeller KI-Assistent
✅ Vollständige Gesprächsspeicherung über alle Interaktionen hinweg
✅ Nahtlos zwischen kreativen, analytischen und technischen Aufgaben wechseln
✅ Benutzerdefinierte Assistenten mit persistentem Kontext und Wissen erstellen
Jetzt starten
Universeller KI-Assistent
✅ Vollständige Gesprächsspeicherung über alle Interaktionen hinweg
✅ Nahtlos zwischen kreativen, analytischen und technischen Aufgaben wechseln
✅ Benutzerdefinierte Assistenten mit persistentem Kontext und Wissen erstellen
Jetzt starten